Paper summary: Occupy the Cloud: Distributed Computing for the 99%
"We are the 99%!" (Occupy Wall Street Movement, 2011)
The 99% that the title of this paper refers to is the non-cloud-native and non-CS-native programmers. Most scientific and analytics software is written by domain experts like biologists and physicists rather than computer scientists. Writing and deploying at the cloud is hard for these folks. Heck it is even hard for the computer science folk. The paper reports that an informal survey at UC Berkeley found that the majority of machine learning graduate students have never written a cluster computing job due to complexity of setting up cloud platforms.
Yes, cloud computing virtualized a lot of things, and VMs, and recently containers, reduced the friction of deploying at the clouds. However, there are still too many choices to make and things to configure before you can get your code to deploy & run at the cloud. We still don't have a "cloud button", where you can push to get your single machine code deployed and running on the cloud in seconds.
But we are getting there. AWS Lambda and Google Cloud Functions aim to solve this problem by providing infrastructure to run event-driven, stateless functions as microservices. In this "serverless" model, a function is deployed once and is invoked repeatedly whenever new inputs arrive. Thus the serverless model elastically scales with input size. Here is an earlier post from me summarizing a paper on the serverless computation model.
This paper, which appeared on arXiv in February 2017 and revised June 2017, pushes the envelope on the serverless model further in order to implement distributed data processing and analytics applications. The paper is a vision paper, so it is low on details at some parts, however a prototype system, PyWren, developed in Python over AWS Lambda, is made available as opensource.
In order to build a data processing system, the paper dynamically injects code into these stateless AWS Lambda functions to circumvent its limits and extend its capabilities. The model has one simple primitive: users submit functions that are executed in a remote container; the functions are stateless; the state as well as input, and output is relegated to the shared remote storage. (This fits well with the rising trend of the disaggregated storage architecture.) Surprisingly, the paper finds that the performance degradation from using such an approach is negligible for many workloads.
After summarizing the code injection approach, I will mention how PyWren can implement increasingly more sophisticated data processing applications ranging from all Map, to Map and monolithic reduce, and MapReduce, and finally a hint of parameter-server implementation.
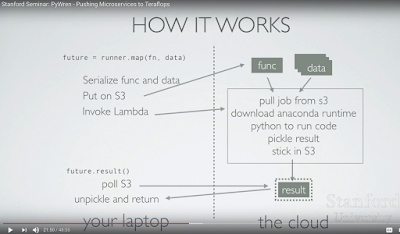
PyWren serializes the user submitted Python function using cloudpickle. PyWren submits the serialized function along with each serialized datum by placing them into globally unique keys in S3, and then invokes a common Lambda function. On the server side, PyWren invokes the relevant function on the relevant datum, both extracted from S3. The result of the function invocation is serialized and placed back into S3 at a pre-specified key, and job completion is signaled by the existence of this key. In this way, PyWren is able to reuse one registered Lambda function to execute different user Python functions and mitigate the high latency for function registration, while executing functions that exceed Lambda’s code size limit.
Map + Monolithic reduce. An easy way to implement MapReduce is to do the Reduce in just one machine. For this one machine to perform reduce, they use a dedicated single r4.16xlarge instance. This machine offers a very large amount of CPU and RAM for $14 an hour.
MapReduce via BSP. To perform Reduce over many workers, we can use the bulk synchronous processing (BSP) model. To implement the BSP model and data shuffling across the stages PyWren leverages the high-bandwidth remote storage AWS S3 provides. To showcase this approach, they implemented a word count program in PyWren and found that on 83M items, it is only 17% slower than PySpark running on dedicated servers.
The paper does not describe how BSP is implemented. I guess this is the responsibility of the driver program on the scientist's laptop. Eric Jonas, one of the authors of this work, calls this the shim handler, that submits the lambda functions to AWS. So I guess this driver checks the progress on the rounds by polling S3, and prepare/invoke the lambda functions for the next round.
The paper also implements a more ambitious application, Terasort, using the PyWren MapReduce. Since this application produces a lot of intermediate files to shuffle in between, they say S3 becomes a bottleneck. So they use AWS elastic cache, a Redis in-memory key-value store. Using this, they show that PyWren can sort 1TB data in 3.4 minutes using 1000 lambda workers.
The Parameter-server implementation. The paper claims to also implement Parameter-Server again using Redis inmemory keyvalue store. But there are no details, so it is unclear if the performance of using that is acceptable.

Using AWS Lambda is only ~2× more expensive than on-demand instances. The paper says that this cost is worthwhile "given substantially finer-grained billing, much greater elasticity, and the fact that many dedicated clusters are often running at 50% utilization".
As for limitations, this works best if the workers do not need to coordinate frequently and use most of the 5 minutes (i.e. 300s) of lambda function execution time for computing over the data input to its 1.5GB RAM to produce the output data. So the paper cautions that for applications like particle simulations, which require a lot of coordination between long running processes, the PyWren model of using stateless functions with remote storage might not be a good fit.
It looks like beyond the map functionality, ease of programming is still not that great. But this is a step in the right direction.
The 99% that the title of this paper refers to is the non-cloud-native and non-CS-native programmers. Most scientific and analytics software is written by domain experts like biologists and physicists rather than computer scientists. Writing and deploying at the cloud is hard for these folks. Heck it is even hard for the computer science folk. The paper reports that an informal survey at UC Berkeley found that the majority of machine learning graduate students have never written a cluster computing job due to complexity of setting up cloud platforms.
Yes, cloud computing virtualized a lot of things, and VMs, and recently containers, reduced the friction of deploying at the clouds. However, there are still too many choices to make and things to configure before you can get your code to deploy & run at the cloud. We still don't have a "cloud button", where you can push to get your single machine code deployed and running on the cloud in seconds.
But we are getting there. AWS Lambda and Google Cloud Functions aim to solve this problem by providing infrastructure to run event-driven, stateless functions as microservices. In this "serverless" model, a function is deployed once and is invoked repeatedly whenever new inputs arrive. Thus the serverless model elastically scales with input size. Here is an earlier post from me summarizing a paper on the serverless computation model.
This paper, which appeared on arXiv in February 2017 and revised June 2017, pushes the envelope on the serverless model further in order to implement distributed data processing and analytics applications. The paper is a vision paper, so it is low on details at some parts, however a prototype system, PyWren, developed in Python over AWS Lambda, is made available as opensource.
In order to build a data processing system, the paper dynamically injects code into these stateless AWS Lambda functions to circumvent its limits and extend its capabilities. The model has one simple primitive: users submit functions that are executed in a remote container; the functions are stateless; the state as well as input, and output is relegated to the shared remote storage. (This fits well with the rising trend of the disaggregated storage architecture.) Surprisingly, the paper finds that the performance degradation from using such an approach is negligible for many workloads.
After summarizing the code injection approach, I will mention how PyWren can implement increasingly more sophisticated data processing applications ranging from all Map, to Map and monolithic reduce, and MapReduce, and finally a hint of parameter-server implementation.
Code injection
An AWS Lambda function gives you 5 minutes (300secs) of execution time at single core and 1.5 Gb RAM, and also gives you 512 MB in /tmp. PyWren exploits this 512MB tmp space to read Anaconda Python Runtime libraries. (This linked talk clarified PyWren code injection for me.)
PyWren serializes the user submitted Python function using cloudpickle. PyWren submits the serialized function along with each serialized datum by placing them into globally unique keys in S3, and then invokes a common Lambda function. On the server side, PyWren invokes the relevant function on the relevant datum, both extracted from S3. The result of the function invocation is serialized and placed back into S3 at a pre-specified key, and job completion is signaled by the existence of this key. In this way, PyWren is able to reuse one registered Lambda function to execute different user Python functions and mitigate the high latency for function registration, while executing functions that exceed Lambda’s code size limit.
Implementing Map, MapReduce, and the Parameter-Server
Map implementation. Many scientific and analytic workloads are embarrassingly parallel. The map primitive provided by PyWren makes addressing these use cases easy. Calling the map launches as many stateless functions as there are elements in the list that one is mapping over.Map + Monolithic reduce. An easy way to implement MapReduce is to do the Reduce in just one machine. For this one machine to perform reduce, they use a dedicated single r4.16xlarge instance. This machine offers a very large amount of CPU and RAM for $14 an hour.
MapReduce via BSP. To perform Reduce over many workers, we can use the bulk synchronous processing (BSP) model. To implement the BSP model and data shuffling across the stages PyWren leverages the high-bandwidth remote storage AWS S3 provides. To showcase this approach, they implemented a word count program in PyWren and found that on 83M items, it is only 17% slower than PySpark running on dedicated servers.
The paper does not describe how BSP is implemented. I guess this is the responsibility of the driver program on the scientist's laptop. Eric Jonas, one of the authors of this work, calls this the shim handler, that submits the lambda functions to AWS. So I guess this driver checks the progress on the rounds by polling S3, and prepare/invoke the lambda functions for the next round.
The paper also implements a more ambitious application, Terasort, using the PyWren MapReduce. Since this application produces a lot of intermediate files to shuffle in between, they say S3 becomes a bottleneck. So they use AWS elastic cache, a Redis in-memory key-value store. Using this, they show that PyWren can sort 1TB data in 3.4 minutes using 1000 lambda workers.
The Parameter-server implementation. The paper claims to also implement Parameter-Server again using Redis inmemory keyvalue store. But there are no details, so it is unclear if the performance of using that is acceptable.

Discussion
They find that it is possible to achieve around 30-40 MB/s write and read performance per core to S3, matching the per-core performance of a single local SSD on typical EC2 nodes. They also show that this scales to 60-80 GB/s to S3 across 2800 simultaneous functions.Using AWS Lambda is only ~2× more expensive than on-demand instances. The paper says that this cost is worthwhile "given substantially finer-grained billing, much greater elasticity, and the fact that many dedicated clusters are often running at 50% utilization".
As for limitations, this works best if the workers do not need to coordinate frequently and use most of the 5 minutes (i.e. 300s) of lambda function execution time for computing over the data input to its 1.5GB RAM to produce the output data. So the paper cautions that for applications like particle simulations, which require a lot of coordination between long running processes, the PyWren model of using stateless functions with remote storage might not be a good fit.
It looks like beyond the map functionality, ease of programming is still not that great. But this is a step in the right direction.







Comments